UC-AI-001AILv4
Agent Web Access(検索+抽出+ブラウザ自動化)
AI エージェントに Web 検索・抽出・ブラウザ操作を持たせ、業務タスクを自律化する。
Agent Web AccessSERP APIBrowser API
KPI 例
- タスク完了率
- 引用率
- 1 タスクあたりコスト
Agent Web Access の価値は、単に「Web から取れる」ことではありません。AI エージェントが、質問内容に応じて 検索する / 対象ページを開く / 必要ならブラウザ操作に切り替える という判断を、1 つの実装面で扱えるようにする点にあります。Bright Data の一次情報では、AI 向けの入口として Agent Web Access と MCP が案内されており、裏側では SERP API や Browser API を使い分ける形が自然です。
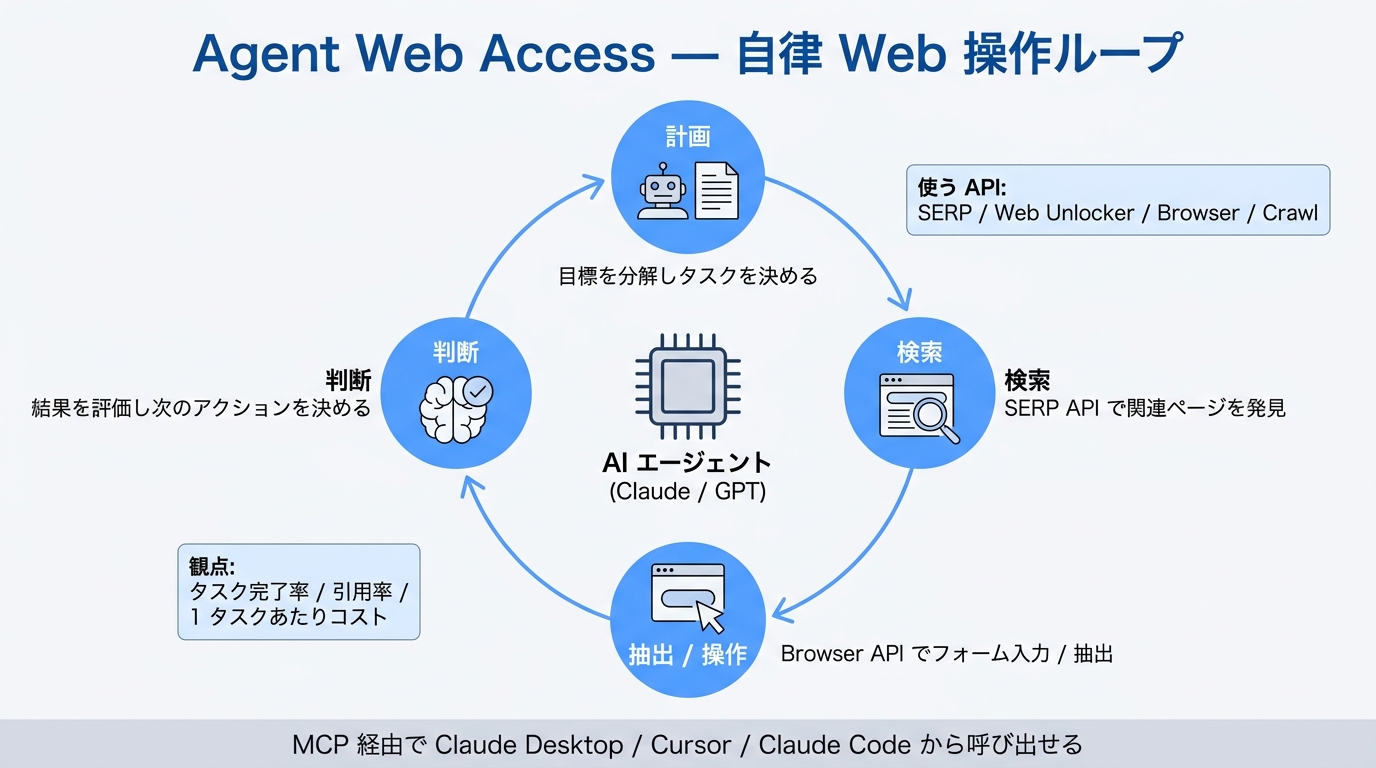
誰の課題か
- 社内リサーチエージェントを作りたい AI エンジニア
- FAQ ボットに外部情報検索と引用を持たせたいアプリ開発者
- 手作業の検索、コピー、ページ確認をエージェントに寄せたい業務自動化担当
検索結果だけで足りるなら SERP API 単体で十分です。DOM 操作やクリックが必要になった時点で Browser API を足し、エージェントから呼ぶ入口として MCP を置くと整理しやすくなります。
推奨製品セット
| 製品 | 役割 | 使い分け |
|---|---|---|
| Agent Web Access | AI ユースケース全体の設計概念 | 検索、抽出、操作を 1 フローで扱う |
| MCP | AI クライアントからの接続面 | Claude、Cursor、社内エージェントの入口 |
| SERP API | 検索結果の構造化取得 | クエリ候補の発見、根拠 URL の初期収集 |
| Browser API | ブラウザ実行 | JS-heavy ページ、クリック、ログイン後確認 |
- まずは MCP 経由で検索を通し、必要になったページだけ Browser API に送る構成が扱いやすいです。
- 取得基盤を 1 つに寄せても、内部では「検索」と「ブラウザ操作」を分離して運用します。
最小実装イメージ
MCP の検索入口を 1 つ用意する
Step 6 の内容に合わせ、ローカルで MCP Server を起動して検索を呼び出す最小例です。
curl -X POST "http://localhost:8080/v1/search" \
-H "Content-Type: application/json" \
-H "X-API-KEY: $BRIGHTDATA_API_KEY" \
-d '{
"query": "Bright Data browser api quickstart",
"engine": "google",
"num_results": 3
}'Python で「検索して上位 URL を返す」ツールを作る
import os
import requests
API_KEY = os.getenv("BRIGHTDATA_API_KEY")
MCP_ENDPOINT = "http://localhost:8080/v1/search"
def agent_search(query: str) -> list[dict]:
response = requests.post(
MCP_ENDPOINT,
headers={
"Content-Type": "application/json",
"X-API-KEY": API_KEY,
},
json={
"query": query,
"engine": "google",
"num_results": 5,
},
timeout=30,
)
response.raise_for_status()
results = response.json().get("results", [])
return [
{
"title": item.get("title"),
"url": item.get("url"),
"snippet": item.get("snippet"),
}
for item in results
]
if __name__ == "__main__":
for row in agent_search("Bright Data MCP overview"):
print(row["title"], row["url"])この段階では検索までに留め、ページ内クリックや入力が必要な URL だけを Browser API 側に回します。ブラウザ操作の実装は ハンズオン Step 5: Browser API + Playwright に寄せると責務が分かれます。
運用ポイント
- 認証は API Access と Native Access を混同しないことが前提です。MCP や SERP API は Bearer または
X-API-KEYで扱い、Browser API は Native Access の接続情報が出てくる場面があります。 - エージェントに最初からブラウザ操作を許可せず、
search -> fetch -> browserの順で昇格させるほうが失敗時の切り分けが簡単です。 - 取得した根拠 URL は回答本文とは別に保持し、引用と監査ログを後で追えるようにします。
- 検索系 zone とブラウザ系 zone を分け、使用量を別々に見ます。Browser API 側のコストとレイテンシは検索より重くなりやすいためです。
- 429 や timeout の再試行は必要ですが、無条件リトライではなく「検索件数を減らす」「Browser API へ切り替える」といった分岐を持たせます。