基礎 / 運用
監視・コスト・権限分離の入り口
Bright Data は、最初の 1 回を通すだけなら数分で始められますが、本番運用では zone 設計、非同期化、レート制御、コスト監視、失敗パターンの分類 が重要です。ここを曖昧にすると、取得できる日とできない日が混ざり、原因追跡も難しくなります。
このページでは、学習サイト全体で共通になる運用の基礎を整理します。認証の前提は 認証ガイド、製品の地図は 基礎 / API グループ を参照してください。
一次情報: Authentication Crawl API Overview Data Feeds introduction
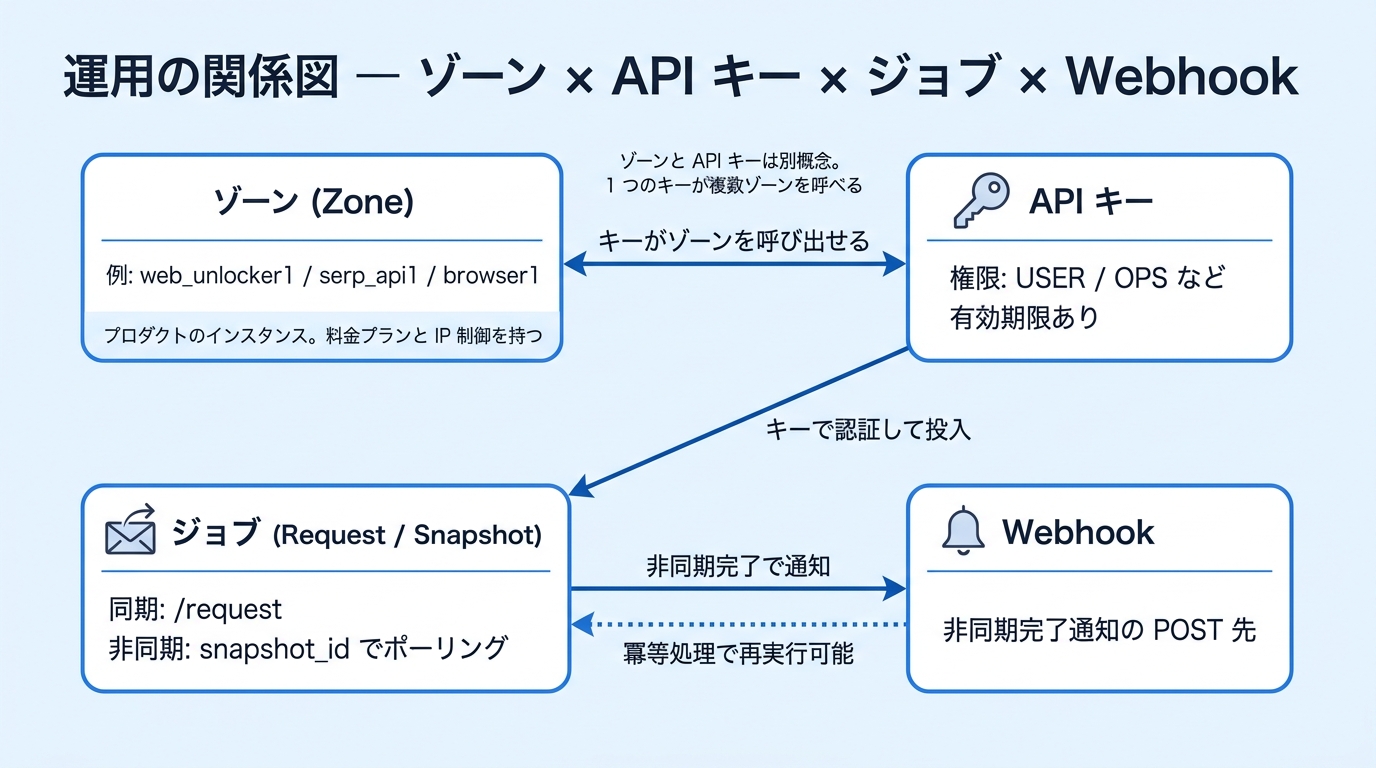
zone 設計
zone は Bright Data の運用単位です。コードの中では単なる文字列に見えますが、実務では 責務の境界 として扱います。
基本ルール
- 検証用と本番用で zone を分ける
- 製品ごとに zone を分ける
- 同じ製品でも用途が違うなら分ける
- zone 名は後で読んで意味がわかる命名にする
例
| zone 名 | 用途 | 典型的な呼び出し元 |
|---|---|---|
serp_dev | SERP API の検証 | ローカル開発、CI |
serp_prod | 順位監視の本番 | 定期ジョブ |
unlocker_catalog | EC 商品ページ取得 | 収集ワーカー |
crawl_docs | ドキュメントクロール | 非同期ジョブ |
browser_login_flow | ログイン後ページ検証 | Playwright |
zone を細かく分ける理由は 3 つあります。
- コストをワークロード単位で見やすくするため
- 問題が出たときに切り離しやすくするため
- パスワードや接続情報の更新を局所化するため
同期と非同期を分けて考える
小さい検証では同期呼び出しで十分ですが、大きなジョブでは非同期を前提にしたほうが安定します。特に Crawl API、Scrapers、Data Feeds のような大量処理では、呼び出し直後に結果を待ち続ける設計は扱いにくくなります。
同期でよいケース
- 1 URL の取得確認
- 少量の SERP テスト
- 開発者が手元でレスポンス形式を確認する段階
非同期に寄せるべきケース
- URL 数が多い
- 取得後に変換、保存、評価の後続処理がある
- 1 回のジョブが数分以上かかる可能性がある
- Webhook や外部ストレージへつなぎたい
非同期運用の最小形
curl -X POST https://api.brightdata.com/datasets/v3/trigger \
-H "Authorization: Bearer $BRIGHTDATA_API_KEY" \
-H "Content-Type: application/json" \
-d '[
{"url":"https://example.com/page-1"},
{"url":"https://example.com/page-2"}
]'上のようなジョブ起動系 API では、即時に全データが返るとは限りません。ジョブ ID、snapshot、Webhook 通知などを軸に後段処理を組みます。
Webhook の考え方
Webhook は、長いジョブを「呼んだ側が待ち続ける」代わりに、「終わったら通知してもらう」ための仕組みです。非同期ジョブを使うなら、ほぼ必須と考えてよいです。
Webhook を使う流れ
- ジョブを起動する
- ジョブ ID や snapshot ID を保存する
- 完了通知を受けるエンドポイントを用意する
- 通知を受けたら結果を取得し、保存や解析に回す
Webhook で最低限やること
- 署名や送信元の検証
- 同じ通知の重複受信に備えた冪等処理
- 失敗時の再取得手段の用意
- タイムアウト時のジョブ状態確認
レート制御
取得失敗の多くは、実装側が速く投げすぎることでも起きます。Bright Data の機能だけでなく、呼び出し元の送信速度を制御する必要があります。
基本方針
- 最初は低い並列度で始める
- 429、403、timeout の比率を見ながら段階的に上げる
- API ごとに上限を別に持つ
- Browser API や Crawl API は、SERP API より重い前提で扱う
単純なバックオフ例
const delays = [1000, 3000, 5000];
for (const delay of delays) {
const response = await fetch(targetUrl, options);
if (response.ok) {
break;
}
await new Promise((resolve) => setTimeout(resolve, delay));
}単純ですが、まずはこれで十分です。重要なのは、失敗を 1 回で諦めるのではなく、分類して再試行の余地を持つことです。
コスト管理
コストは「製品」「件数」「頻度」「出力形式」の掛け合わせで増えます。学習段階では費用が小さくても、本番移行時に件数が 100 倍になることは珍しくありません。
先に決めるべきこと
| 項目 | 決め方 |
|---|---|
| 集計単位 | zone 単位で見る |
| 上限 | 日次または週次で予算を持つ |
| アラート | 失敗率とコストの両方で通知する |
| 再取得 | 同一 URL の無駄打ちを防ぐ |
コストが膨らみやすい場面
- 検証用スクリプトを本番と同じ頻度で回す
- Browser API を、HTML だけで足りるページにも使う
- Crawl API で対象範囲を広げすぎる
- 同じ URL を差分確認なしで何度も取り直す
抑え方の実務ルール
- まず SERP、Unlocker、Browser、Crawl のどれが最小コストで足りるかを見極める
- 差分検知や更新頻度の設計を先に行う
- 検証 zone に日次上限を設ける
- 非同期ジョブの結果は保存し、再利用する
失敗パターンの分類
運用で重要なのは、すべてを「取得失敗」と一括りにしないことです。原因ごとに対処が違います。
403
403 は、アクセス制限、認証不足、サイト側ブロックのいずれかです。まず対象 API、zone、URL、直前の成功率を確認します。Unlocker で改善するのか、Browser API が必要なのか、あるいは単純に権限ミスなのかを切り分けます。
対応の型:
- zone の誤り、API キー権限、URL 誤記を確認する
- HTML 取得で詰まるなら Web Unlocker を検討する
- JavaScript 依存なら Browser API へ切り替える
CAPTCHA
CAPTCHA は、取得対象がボット対策を強めているサインです。自前で突破ロジックを持つより、まず製品選定を見直します。SERP なら SERP API、保護ページなら Unlocker、操作型サイトなら Browser API を検討します。
対応の型:
- 単純 HTTP 取得をやめ、専用 API へ寄せる
- リクエスト速度を落とす
- 同一ターゲットへの集中アクセスを避ける
timeout
timeout は、対象サイトの応答遅延、ブラウザ実行の重さ、こちらのタイムアウト値不足のどれかです。闇雲に待ち時間だけ伸ばすと、ワーカーが詰まりやすくなります。
対応の型:
- タイムアウトを API ごとに分ける
- 重い処理は非同期ジョブに逃がす
- 再試行回数を決め、無限リトライを避ける
parsing drift
parsing drift は、対象サイトの HTML 構造や DOM が変わって、抽出ロジックが静かに壊れる状態です。最も見逃しやすく、運用で頻出します。取得成功率だけでは検知できないことが多いです。
対応の型:
- 件数だけでなく必須フィールド欠損率を監視する
- サンプル HTML や JSON を定期保存する
- 自前パーサを使うならスナップショットテストを置く
- 既製 Scrapers がある対象は、そちらを優先する
運用 Runbook の最小構成
本番導入前に、次の 6 項目だけは文章化しておくと事故が減ります。
- zone 一覧と責務
- API キーの権限と期限
- 失敗時の一次切り分け手順
- Webhook の再送・冪等処理
- コストの確認方法
- パーサ変更時のテスト手順
学習段階ごとの運用目標
| レベル | 目標 |
|---|---|
| Lv1 | API キーと zone を混同しない |
| Lv2 | 403、timeout、CAPTCHA を分類できる |
| Lv3 | 非同期ジョブと Webhook を組み込める |
| Lv4 | MCP やエージェント経由でも評価指標を置ける |
| Lv5 | 権限分離、監査、SLA を文書化できる |
最小チェックリスト
- zone は検証用と本番用で分かれているか
- API キーは最小権限か
- 同期と非同期の使い分けが決まっているか
- Webhook の冪等処理があるか
- 403 / CAPTCHA / timeout / parsing drift を別々に観測しているか
- コストを zone 単位で見ているか