Step 3 ・ Lv3 ・ 目安 120 分
Step 3 Crawl API で RAG 前処理
複数 URL を Crawl API で取得し、Markdown に整形、最小 RAG の入力として取り込む。
リード文
この手順を完了すると、複数の Web ページを Bright Data の Crawl API で取得し、Markdown に整形した後、トークン単位でチャンク分割し埋め込みを生成、ローカルの Chroma ベクトル DB に保存できます。最後に、最小限の RAG クエリで検索結果を取得できるようになります。
ゴールと所要時間
-
ゴール
- 複数 URL を Crawl API で取得し Markdown に整形
- チャンク分割 → 埋め込み生成 → Chroma(または Weaviate)に投入
- 最小の RAG クエリを実行し、検索結果を取得
-
所要時間:120 分
-
難易度:Lv3(中級)
前提
- Step 1 が完了していること(Crawl API のゾーン取得、認証情報取得済み)
- Crawl API のゾーン(例:
us-east-1) が判明していること - OpenAI または Anthropic の API キーが取得済みであること
- Python 3.10+ がインストールされていること
- Node.js 18+ がインストールされていること
環境変数は次の通りに設定してください(シークレットは直書きしない)
export BRIGHTDATA_API_KEY="YOUR_BRIGHTDATA_API_KEY"
export OPENAI_API_KEY="YOUR_OPENAI_API_KEY"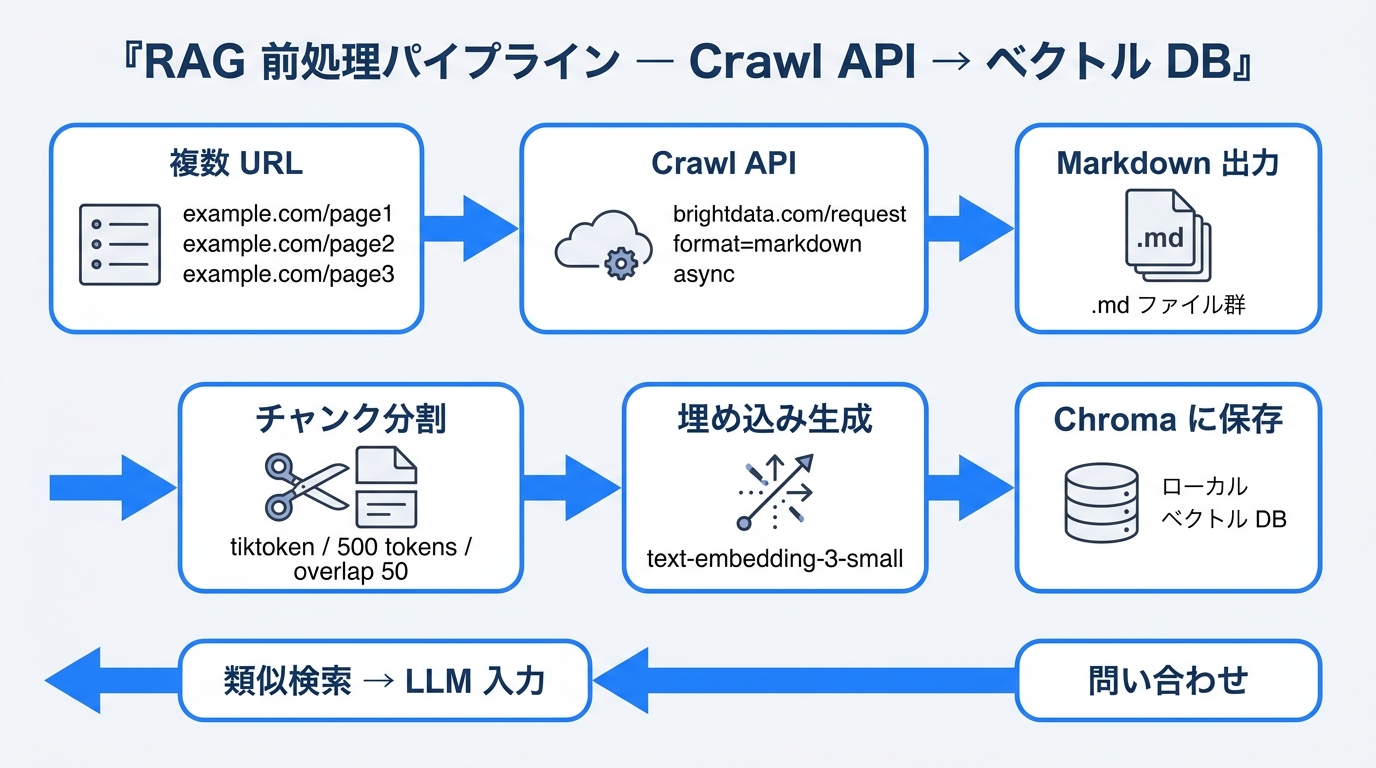
手順 1: Crawl API の非同期ジョブ投入(curl) → status ポーリング → 結果ダウンロード
1‑1 ジョブ投入
# urls.json 例
cat > urls.json <<'EOF'
{
"urls": [
"https://example.com/article1",
"https://example.com/article2",
"https://example.com/article3"
],
"output": "markdown"
}
EOF
# 非同期ジョブ作成
JOB_ID=$(curl -s -X POST "https://api.brightdata.com/v1/crawl/jobs" \
-H "Authorization: Bearer $BRIGHTDATA_API_KEY" \
-H "Content-Type: application/json" \
-d @urls.json | jq -r '.job_id')
echo "Created job: $JOB_ID"1‑2 ステータス・ポーリング
# 10 秒ごとにステータス確認、完了までループ
while true; do
STATUS=$(curl -s -X GET "https://api.brightdata.com/v1/crawl/jobs/$JOB_ID/status" \
-H "Authorization: Bearer $BRIGHTDATA_API_KEY" | jq -r '.status')
echo "Job status: $STATUS"
if [[ "$STATUS" == "completed" ]]; then
break
elif [[ "$STATUS" == "failed" ]]; then
echo "Job failed"
exit 1
fi
sleep 10
done1‑3 結果ダウンロード
curl -s -X GET "https://api.brightdata.com/v1/crawl/jobs/$JOB_ID/result?format=markdown" \
-H "Authorization: Bearer $BRIGHTDATA_API_KEY" \
-o crawl_results.md
echo "Results saved to crawl_results.md"手順 2: Python で複数 URL を一括投入するスクリプト
# crawl_bulk.py
import os
import json
import time
import requests
BRIGHTDATA_API_KEY = os.getenv("BRIGHTDATA_API_KEY")
BASE_URL = "https://api.brightdata.com/v1/crawl/jobs"
def create_job(urls, output="markdown"):
payload = {"urls": urls, "output": output}
resp = requests.post(
BASE_URL,
headers={"Authorization": f"Bearer {BRIGHTDATA_API_KEY}", "Content-Type": "application/json"},
json=payload,
)
resp.raise_for_status()
return resp.json()["job_id"]
def poll_job(job_id, interval=10):
status_url = f"{BASE_URL}/{job_id}/status"
while True:
r = requests.get(status_url, headers={"Authorization": f"Bearer {BRIGHTDATA_API_KEY}"})
r.raise_for_status()
status = r.json()["status"]
print(f"Job {job_id} status: {status}")
if status == "completed":
return
if status == "failed":
raise RuntimeError("Crawl job failed")
time.sleep(interval)
def download_result(job_id, out_path="result.md"):
result_url = f"{BASE_URL}/{job_id}/result?format=markdown"
r = requests.get(result_url, headers={"Authorization": f"Bearer {BRIGHTDATA_API_KEY}"})
r.raise_for_status()
with open(out_path, "w", encoding="utf-8") as f:
f.write(r.text)
print(f"Saved result to {out_path}")
if __name__ == "__main__":
urls = [
"https://example.com/article1",
"https://example.com/article2",
"https://example.com/article3",
]
job_id = create_job(urls)
print(f"Created job {job_id}")
poll_job(job_id)
download_result(job_id, "crawl_results.md")実行方法:
python3 crawl_bulk.py手順 3: Markdown 出力を受け取りチャンク分割(tiktoken, 500 tokens overlap 50)
# chunk_md.py
import os
import tiktoken
from pathlib import Path
MODEL = "gpt-4" # tiktoken のエンコーダーはモデル名で決定
MAX_TOKENS = 500
OVERLAP = 50
INPUT_FILE = Path("crawl_results.md")
OUTPUT_DIR = Path("chunks")
OUTPUT_DIR.mkdir(exist_ok=True)
def load_md(path: Path) -> str:
return path.read_text(encoding="utf-8")
def split_into_chunks(text: str, max_tokens: int, overlap: int):
enc = tiktoken.encoding_for_model(MODEL)
tokens = enc.encode(text)
i = 0
while i < len(tokens):
chunk_tokens = tokens[i : i + max_tokens]
yield enc.decode(chunk_tokens)
i += max_tokens - overlap
def main():
md = load_md(INPUT_FILE)
for idx, chunk in enumerate(split_into_chunks(md, MAX_TOKENS, OVERLAP)):
out_path = OUTPUT_DIR / f"chunk_{idx:03d}.md"
out_path.write_text(chunk, encoding="utf-8")
print(f"Saved {out_path}")
if __name__ == "__main__":
main()pip install tiktoken
python3 chunk_md.pychunks/ ディレクトリに chunk_000.md, chunk_001.md … が生成されます。
手順 4: 埋め込み生成(OpenAI text-embedding-3-small 例)
# embed_chunks.py
import os
import json
from pathlib import Path
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
CHUNK_DIR = Path("chunks")
EMBED_DIR = Path("embeddings")
EMBED_DIR.mkdir(exist_ok=True)
MODEL = "text-embedding-3-small"
def embed(text: str):
resp = openai.Embedding.create(
model=MODEL,
input=text,
)
return resp["data"][0]["embedding"]
def main():
for md_path in sorted(CHUNK_DIR.glob("*.md")):
chunk_id = md_path.stem
embed_path = EMBED_DIR / f"{chunk_id}.json"
if embed_path.exists():
continue
text = md_path.read_text(encoding="utf-8")
vec = embed(text)
embed_path.write_text(json.dumps({"text": text, "embedding": vec}), ensure="utf-8")
print(f"Embedded {md_path.name}")
if __name__ == "__main__":
main()pip install openai
python3 embed_chunks.py手順 5: Chroma (ローカル) に保存し、問い合わせ
# chroma_rag.py
import os
import json
from pathlib import Path
import chroma
CHUNK_DIR = Path("chunks")
EMBED_DIR = Path("embeddings")
DB_PATH = "chroma_db"
def load_embeddings():
docs = []
vectors = []
for embed_file in sorted(EMBED_DIR.glob("*.json")):
data = json.loads(embed_file.read_text(encoding="utf-8"))
docs.append(data["text"])
vectors.append(data["embedding"])
return docs, vectors
def main():
docs, vectors = load_embeddings()
client = chroma.Client()
collection = client.create_collection(name="ragu_collection", embedding_function=None)
collection.add(
ids=[f"doc_{i}" for i in range(len(docs))],
documents=docs,
embeddings=vectors,
)
print("Data stored in Chroma DB")
# 最小クエリ例
query = "AI の最新トレンドは何ですか?"
results = collection.query(
query_texts=[query],
n_results=3,
)
print("Top 3 results:")
for doc in results["documents"][0]:
print("-" + doc[:200].replace("\n", " ") + "...")
if __name__ == "__main__":
main()pip install chromadb tqdm
python3 chroma_rag.py手順 6: Node.js 版の最小ポーリングコード
// poll_job.js
import fetch from "node-fetch";
const BRIGHTDATA_API_KEY = process.env.BRIGHTDATA_API_KEY;
const JOB_ID = process.argv[2]; // 例: node poll_job.js <job_id>
async function getStatus(jobId) {
const res = await fetch(`https://api.brightdata.com/v1/crawl/jobs/${jobId}/status`, {
headers: { Authorization: `Bearer ${BRIGHTDATA_API_KEY}` },
});
const data = await res.json();
return data.status;
}
async function poll(jobId, interval = 10000) {
while (true) {
const status = await getStatus(jobId);
console.log(`Job ${jobId} status: ${status}`);
if (status === "completed") break;
if (status === "failed") throw new Error("Job failed");
await new Promise((r) => setTimeout(r, interval));
}
console.log("Job completed!");
}
poll(JOB_ID).catch(console.error);実行例:
node poll_job.js $JOB_IDトラブルシューティング
| 症状 | 原因 | 対策 |
|---|---|---|
ジョブが長時間 running のまま | 取得 URL の数が多すぎ、またはページが巨大 | urls.json の件数を減らす、または output を text に変更しサイズを削減 |
curl で 504 Gateway Timeout | ネットワーク不安定または API のレートリミット | リトライロジックを追加し、Retry-After ヘッダーを尊守 |
Python で tiktoken がエラー | モデル名がサポート外 | MODEL を gpt-3.5-turbo などに変更 |
| OpenAI 埋め込みが遅い | バッチ処理していない | openai.Embedding.create に input にリストを渡し、バッチで取得 |
| Chroma 起動エラー | ディスク容量不足 | DB_PATH を外部 SSD に変更、または不要なコレクションを削除 |