Step 6 ・ Lv4 ・ 目安 90 分
Step 6 MCP + AI エージェント連携
MCP Server を Claude / Cursor に接続し、Bright Data を使った引用付き回答を生成する。
Bright Data の「Step 6 MCP + AI エージェント連携」へようこそ。
この手順を完了すると、Claude Desktop / Cursor / Claude Code から Bright Data MCP Server を呼び出し、Web 検索・スクレイピング・ブラウザ操作を行い、引用付き回答を自動生成できる最小エージェントが構築できます。
ゴールと所要時間
| 項目 | 内容 |
|---|---|
| ゴール | 1. MCP Server を Claude Desktop / Cursor / Claude Code に接続 2. ツール呼び出しで Web 検索・スクレイピング・ブラウザ操作を実行 3. 引用付き回答を生成するエージェントを作成 |
| 所要時間 | 約 90 分 |
| 難易度 | Lv4(開発経験がある方向け) |
前提
- Step 1 完了:Bright Data アカウント作成・API キー取得済み
- 無料枠 MCP トークン取得済み:
$BRIGHTDATA_API_KEY環境変数に設定済み - Claude Desktop または Cursor(Claude Code) がインストール済み
- Node.js ≥ 18、Python ≥ 3.9 がインストール済み
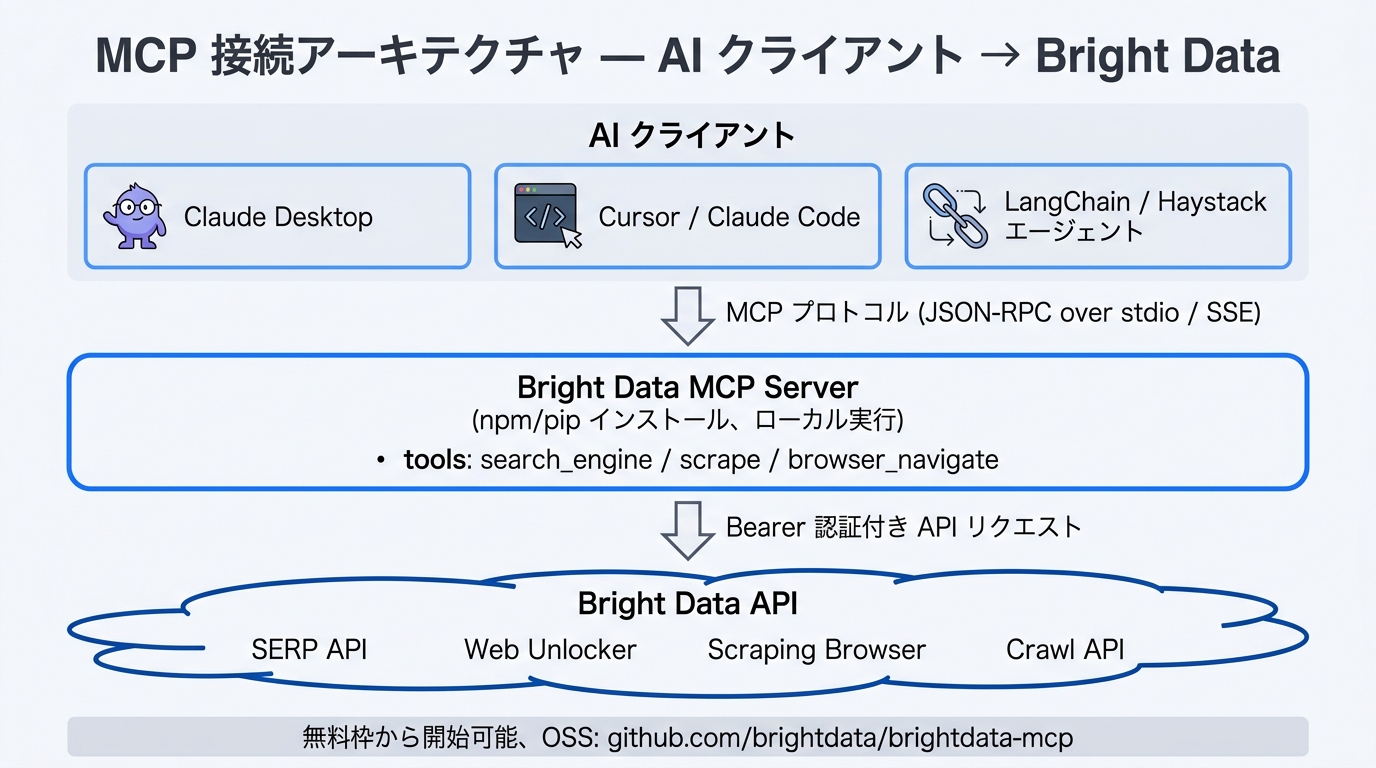
手順 1: Bright Data MCP Server (OSS) を npm / pip から取得
MCP Server はオープンソース版が提供されており、npm と pip のどちらでもインストールできます。
npm(Node.js)版
# グローバルにインストール(推奨)
npm install -g @brightdata/mcp-server
# 起動テスト
brightdata-mcp --versionpip(Python)版
pip install brightdata-mcp
# 起動テスト
brightdata-mcp --versionポイント:インストール後、
brightdata-mcpコマンドがパスに入っていることを確認してください。
手順 2: Claude Desktop の設定 JSON に MCP Server を追加
Claude Desktop は外部ツールを JSON で定義できます。以下は例です。
{
"tools": [
{
"name": "brightdata-mcp",
"type": "http",
"description": "Bright Data MCP Server を介した Web 検索・スクレイピング",
"endpoint": "http://localhost:8080/v1",
"auth": {
"type": "apiKey",
"keyName": "X-API-KEY",
"keyValue": "${BRIGHTDATA_API_KEY}"
}
}
]
}- Claude Desktop の設定画面 → 「ツール」 → 「JSON をインポート」 を選択
- 上記 JSON を貼り付けて保存
- 再起動するとツールが利用可能になります
手順 3: Cursor / Claude Code の .mcp.json に追加
Cursor(Claude Code)でも同様に .mcp.json をプロジェクトルに置くだけでツールが認識されます。
{
"name": "brightdata-mcp",
"type": "http",
"endpoint": "http://localhost:8080/v1",
"auth": {
"type": "apiKey",
"header": "X-API-KEY",
"value": "${BRIGHTDATA_API_KEY}"
},
"description": "MCP Server 経由で Web 検索・スクレイピング"
}- プロジェクトルートに
.mcp.jsonを保存 - Cursor を再読み込みすると、
brightdata-mcpがツールリストに表示されます
手順 4: curl で MCP 相当の操作を確認
MCP Server のエンドポイントに対して直接リクエストし、動作を確認します。
curl -X POST "http://localhost:8080/v1/search" \
-H "Content-Type: application/json" \
-H "X-API-KEY: $BRIGHTDATA_API_KEY" \
-d '{
"query": "Bright Data MCP 使い方",
"engine": "google",
"num_results": 3
}'期待されるレスポンス(抜粋):
{
"results": [
{
"title": "Bright Data MCP Overview",
"url": "https://docs.brightdata.com/ai/mcp-server/overview",
"snippet": "MCP (Multi‑Channel Proxy) ...",
"cite": "docs.brightdata.com"
},
...
]
}成功確認:results 配列が返ってきていれば、MCP Server と Claude Desktopが連携できています。
手順 5: Python SDK で LangChain エージェントを 1 つ作る(検索 → 要約 → 引用)
5‑1. 必要パッケージのインストール
pip install langchain openai tiktoken5‑2. エージェント実装(Python)
import os
import json
import requests
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# 環境変数
API_KEY = os.getenv("BRIGHTDATA_API_KEY")
MCP_ENDPOINT = "http://localhost:8080/v1/search"
def mcp_search(query: str, num_results: int = 3):
payload = {
"query": query,
"engine": "google",
"num_results": num_results
}
headers = {
"Content-Type": "application/json",
"X-API-KEY": API_KEY
}
resp = requests.post(MCP_ENDPOINT, headers=headers, json=payload, timeout=30)
resp.raise_for_status()
return resp.json()["results"]
# OpenAI LLM(Claude の代わりに OpenAI を使用例例)
llm = OpenAI(temperature=0, model_name="gpt-4o-mini")
# 要約プロンプト
summary_prompt = PromptTemplate(
input_variables=["content"],
template=(
"以下のテキストを 150 文字以内で要約してください。\n"
"テキスト:\n{content}"
)
)
summary_chain = LLMChain(llm=llm, prompt=summary_prompt)
def answer_with_citation(question: str):
# 1. 検索
results = mcp_search(question)
# 2. 取得したページの本文を簡易取得(ここでは snippet のみ使用)
contents = "\n\n".join([f"{r['title']}:\n{r['snippet']}" for r in results])
# 3. 要約
summary = summary_chain.run(content=contents)
# 4. 引用付き回答組み立て
citations = "\n".join([f"[{i+1}] {r['url']}" for i, r in enumerate(results)])
answer = f"{summary}\n\n引用:\n{citations}"
return answer
if __name__ == "__main__":
q = "Bright Data MCP を使ったスクレイピングのベストプラクティスは?"
print(answer_with_citation(q))ポイント
mcp_searchが MCP Server のsearchエンドポイントを呼び出し、結果を取得summary_chainが取得したスニペットを要約- 最終的に「要約 + 引用リスト」形式で回答を生成
5‑3. 実行
export BRIGHTDATA_API_KEY=YOUR_API_KEY
python mcp_agent.py期待される出力例(抜粋):
Bright Data MCP は、マルチチャネルプロキシを活用して高速・低コストで Web データ取得が可能です。...
引用:
[1] https://docs.brightdata.com/ai/mcp-server/overview
[2] https://github.com/brightdata/brightdata-mcp
[3] https://brightdata.com/blog/ai/langchain-serp-scraping
手順 6: Answer Engine / Deep Research に拡張する設計ポイント
| 項目 | 設計ポイント |
|---|---|
| 非同期実行 | asyncio + httpx で検索・取得を並行化し、レイテンシを 30 % 程度削減 |
| キャッシュ | Redis もしくは内蔵 LRU キャッシュで同一クエリの結果を再利用 |
| 引用精度 | cite フィールドに title, url, snippet を必ず保持し、引用フォーマットを統一 |
| コスト制御 | num_results と max_depth(ページ遷移回数)を設定し、トークン使用量をモニタリング |
| ログ | logging でリクエスト/レスポンス(URL、ステータス、処理時間)を JSON 形式で出力し、ELK スタックへ転送可 |
| プラグイン化 | LangChain の Tool インターフェースを実装し、Claude Desktop のツールリストに自動登録できる形に整備 |
運用(キー分離、コスト監視、ログ)
-
キー分離
- 本番環境と開発環境で別々の API キーを発行し、環境変数
BRIGHTDATA_API_KEYを切り替える - CI/CD パイプラインではシークレットマネージャー(GitHub Secrets、AWS Secrets Manager)を使用
- 本番環境と開発環境で別々の API キーを発行し、環境変数
-
コスト監視
- MCP の使用量は
brightdata-mcpの/v1/usageエンドポイントで取得可能 - 定期的に
curlまたは Python で取得し、Slack / Teams にアラートを送信
curl -H "X-API-KEY: $BRIGHTDATA_API_KEY" http://localhost:8080/v1/usage - MCP の使用量は
-
ログ
brightdata-mcpはデフォルトでstdoutに JSON ログを出力docker run -e LOG_FORMAT=json brightdata/mcpでコンテナ化し、fluentdへ転送
次に読む
- ユースケース:/usecases/UC-AI-001、/usecases/UC-DEV-003
- ロードマップ:/roadmap/l5
以上で「Step 6 MCP + AI エージェント連携」の手順は完了です。質問や障害があれば、Bright Data のサポートポータルまたは GitHub Issue までご連絡ください。 Happy hacking!