Bright Data とは
プロキシ・スクレイピング API・既製データセットの 3 軸で「何ができるか」を初心者向けに整理し、活用事例から技術習得への入口までをつなぐサービス理解の入口ページ。
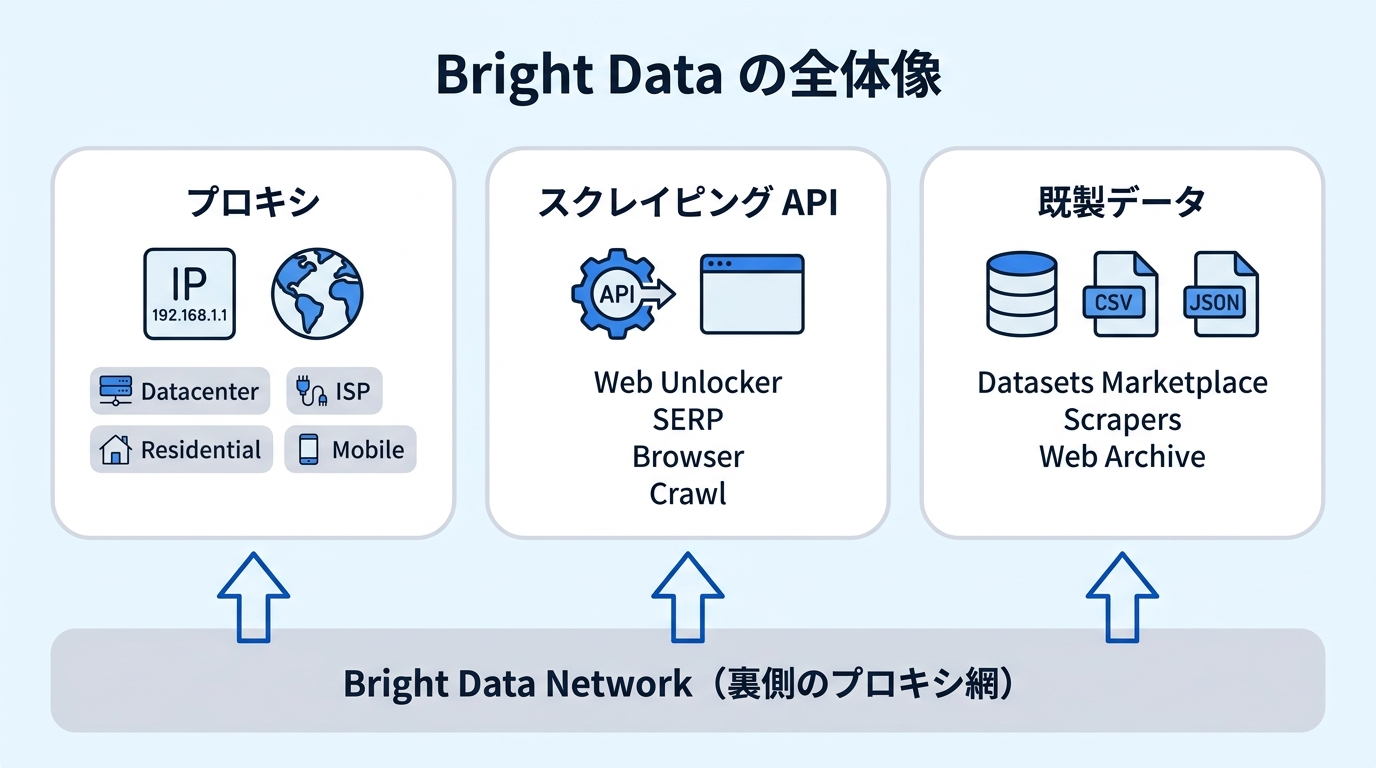
Bright Data は 「Web 上の公開情報を、ブロックや IP 制限を気にせず安全に取得する」ことに特化したインフラ企業です。提供物を大きくまとめると次の 3 つになります。
- プロキシネットワーク — どこからアクセスしているかを切り替える IP の集まり
- スクレイピング API / ブラウザ — ブロックや CAPTCHA、JS 描画を吸収して中身を取れる仕組み
- 既製データセット — もう Bright Data が集め終えた構造化データを買って使う
このページでは「何ができるか」のイメージを掴んだうえで、活用事例と技術習得の導線につなげます。手を動かす前に、まず 5〜10 分で全体像を頭に入れてください。
全体像
| 軸 | 何をするもの | 代表的に解ける課題 |
|---|---|---|
| プロキシ | 「別の IP / 別の国」からアクセスしているように見せる | ブロック回避・地域別の見え方確認・大量並列アクセス |
| スクレイピング API | HTTP / ブラウザ / 検索 API でページの中身を取得する | 価格・在庫・レビュー・SERP・SPA・サイト全体クロール |
| 既製データ | Bright Data があらかじめ集めたデータを購入・取得する | EC・SNS・求人・不動産などの即時分析 |
これらは独立しているわけではなく、「裏側のプロキシ網の上に、用途特化のスクレイピング API と既製データが載っている」 構造です。難易度の低い順では「既製データ → スクレイピング API → プロキシで自前実装」の並びになります。
プロキシでできること
プロキシは、自分の PC やサーバーから直接サイトにアクセスする代わりに 「別の IP の代理」を経由してアクセスする 仕組みです。
- IP を変える → ブロックされにくくする
- 国・都市を変える → 海外ユーザーとしてアクセスする
- 同時に多数の IP を使う → 大量並列の収集をさばく
Bright Data には 4 種類のプロキシがあり、「どのくらい本物のユーザーに見えるか」と「速さ・コスト」のトレードオフ で選びます。
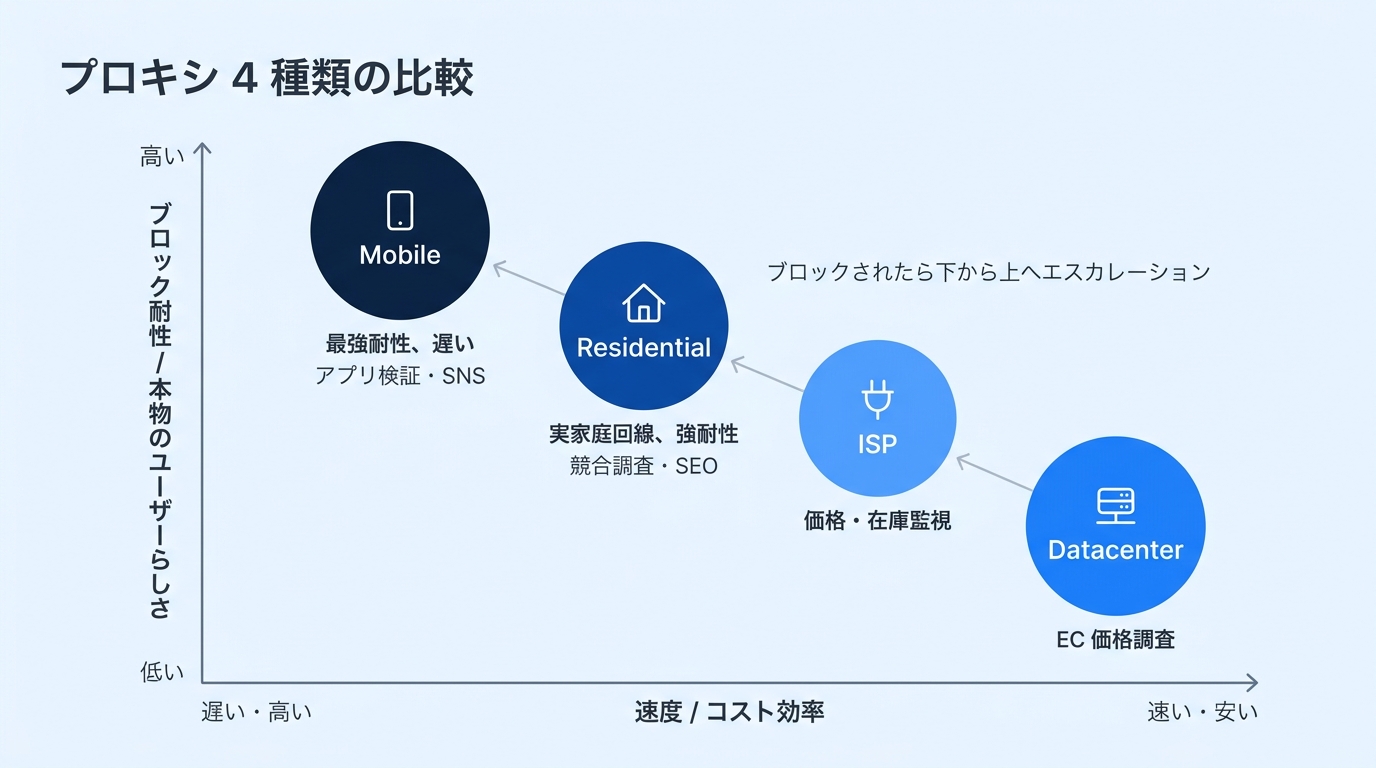
| プロキシ | IP の出自 | 速度 | ブロック耐性 | 向いている場面 |
|---|---|---|---|---|
| Datacenter | データセンター | 高 | 低〜中 | ブロックが緩いサイト、ニュース、検証用途 |
| ISP | プロバイダから取得した実 IP | 高 | 中 | Datacenter で弾かれ始めた次の選択肢 |
| Residential | 家庭の回線・端末 | 中 | 高 | EC 価格調査・競合調査・広告検証 |
| Mobile | 実際のスマホ回線(3G/4G/5G) | 中 | 最高 | モバイル特化サイト・厳しい検知ロジック |
迷ったら、まずは Datacenter で試して、弾かれたら ISP → Residential → Mobile に上げる 順で考えると無駄がありません。
詳しくは 基礎: 製品グループの地図 と用語集のプロキシ用語を参照してください。
スクレイピング API / ブラウザでできること
「プロキシは自分で組んだことがない」「ページの中身さえ取れればいい」という場合は、こちらの製品群が近道です。
用語の補足: CAPTCHA =「私はロボットではありません」型の人間判定 / JS 描画 = JavaScript で組み立てられるページ(React や Vue の SPA など)/ SERP = 検索結果ページ / CDP = Chrome を外部から操作するプロトコル。詳しい定義は用語集を参照。
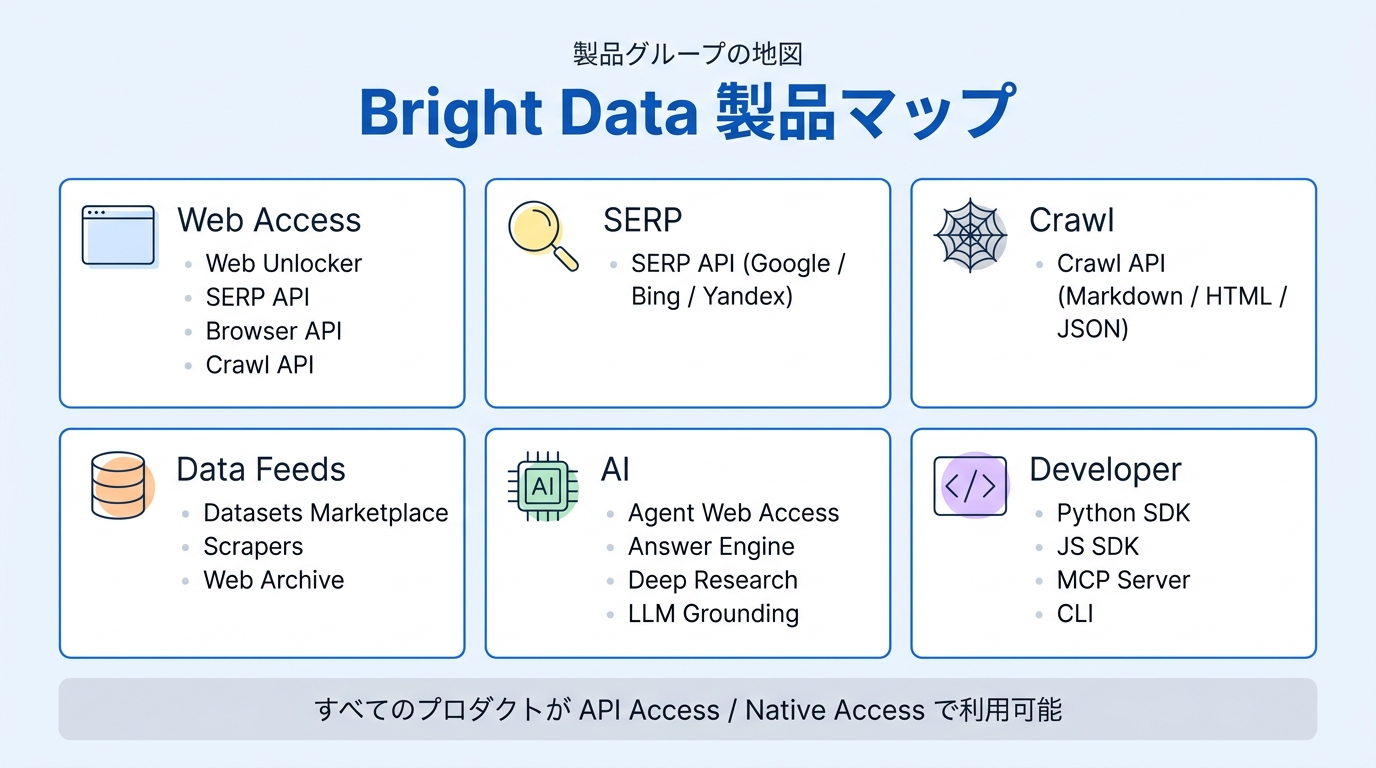
- Web Unlocker —
POST /requestを投げるだけで、ブロック・CAPTCHA・JS 描画を Bright Data 側で吸収して HTML を返してくれる API。最も汎用。 - SERP API — Google / Bing / Yandex などの検索結果を JSON で取得する API。順位監視・ブランド保護・価格比較などの基盤。
- Browser API(Scraping Browser) — Playwright / Puppeteer / Selenium から CDP で接続するリモートブラウザ。ログイン後画面・無限スクロール・厳しい SPA に強い。
- Crawl API — URL リストやドメイン全体を非同期にクロールし、Markdown / HTML / JSON で出力。LLM 学習や RAG(外部データを LLM に渡す手法)前処理向け。
- Scrapers(プリビルト) — Amazon / YouTube / LinkedIn などの主要サイト向けに Bright Data 側がメンテし続けている スクレイパー。サイト仕様が変わっても Bright Data 側で追従してくれるので、初心者が「特定サイトのデータが欲しい」場合の一番簡単な入口です。
- Scraper Studio — Bright Data 上で JavaScript を書いてスクレイパーを作る IDE。AI に「このサイトから△△を取るスクレイパーを作って」と指示してコード生成 → スケジュール実行や Webhook 連携まで一気通貫に組めます。
- MCP Server — AI アシスタント(Claude Desktop / Cursor / Claude Code 等)から Bright Data の検索・取得・ブラウザ操作を「ツール」として呼べるようにする接続口。エージェントに Web を扱わせるときの入口。
- Agent Web Access — 上記 MCP やプロダクトを束ね、AI エージェントが「検索 → 抽出 → ブラウザ操作」を自律的に判断するための設計コンセプト。
それぞれの詳細と使い分けは 基礎: 製品グループの地図 にまとまっています。
既製データを買う / 取り出す
「自分でスクレイピングしたくない」「すぐ分析したい」場合は、Bright Data がすでに集めて構造化したデータを使えます。
- Datasets Marketplace — EC(Amazon ほか)、SNS(LinkedIn ほか)、不動産・旅行・B2B などの構造化データを範囲指定で購入。CSV / JSON で受け取って即日分析に回せます。
- Scrapers(マネージド運用) — 「特定サイト向けのスクレイパーを Bright Data 側で構築・運用してほしい」というオーダーメイド運用。コードは書かず、要件を伝えるだけ。
- Web Archive — Web Unlocker / SERP API で過去に取得されたページのスナップショットを検索・エクスポートできる仕組み。新しくクロールするコストを抑えて過去データを集める用途に向きます。
あなたはどれに近い?
最初に触るべき製品は、やりたいことの 1 行 で決まります。
| やりたいこと | 最初に触る製品 | 次に読むページ |
|---|---|---|
| ブラウザで海外サイトを別の国から見たい | Datacenter / Residential Proxy | 基礎: 製品グループの地図 |
| 特定サイト(Amazon / YouTube 等)のデータを CSV で欲しい | Scrapers(プリビルト) | UC-FEED-003 Amazon 商品・レビュー収集 |
| 検索結果(順位・広告・画像)を継続的に取りたい | SERP API | UC-SERP-001 順位監視 |
| JS 描画 / ログイン後ページを自動で開きたい | Browser API + Playwright | Step 5 Browser API + Playwright |
| 自分でコードを書いてスクレイピングしたい | Web Unlocker → Browser API | Step 1 認証完全ガイド |
| AI エージェントから Web を扱わせたい | MCP Server / Agent Web Access | UC-AI-001 Agent Web Access |
| すぐ分析したい / 自分で集めたくない | Datasets Marketplace | UC-FEED-002 Marketplace 既製データ活用 |
| 既存クローラのブロック回避を強化したい | Web Unlocker / Residential Proxy | UC-WEB-001 保護サイトの安定収集基盤 |
学び方ステップ
このサイトは「理解 → イメージ → 技術習得」の 3 段階で迷わず進めるように作っています。
- 理解: このページで全体像を掴む
- イメージ: 40 ユースケースから、自分の業務に近いものを 2〜3 個読む
- 技術習得:
- 認証の理屈を 認証ガイド で理解
- ロードマップ Lv1〜Lv5 で現在地と目的地を決める
- ハンズオン Step 1 で実際に最初の API を叩く
次に読む
- 40 ユースケース一覧 — 業務起点で「自分はこれだ」を見つける
- 基礎: 製品グループの地図 — 製品ごとの責務と使い分け
- 認証ガイド — API Access / Native Access の最短理解
- ロードマップ Lv1 — 入門レベルから順に学ぶ
- Step 1 認証完全ガイド — まず 1 回 API を叩く