Step 5 ・ Lv3 ・ 目安 120 分
Step 5 Browser API + Playwright
Browser API と Playwright を接続し、JS 描画サイトから必要データを抽出する。
この手順を完了すると、Bright Data の Scraping Browser(CDP エンドポイント)に Playwright(Node.js・Python)で接続し、JavaScript 描画サイトやログイン必須サイト、無限スクロールページを自動取得できるようになります。さらに、セッションを保持したままスクリーンショットや PDF を出力し、CAPTCHA 回避の基本パターンも体得できます。
ゴールと所要時間
- ゴール:Scraping Browser に Playwright を接続し、ログインフロー・無限スクロール・スクリーンショット・PDF 出力を実装
- 所要時間:120 分
- 難易度:Lv3(中級)
前提
- Step 1 が完了していること(Bright Data アカウント取得、API キー取得)
- Scraping Browser のゾーンが作成済みで、CDP エンドポイントが発行されていること
- Node.js 20+ または Python 3.9+ がインストール済みで、
npm/pipが使用できること - 環境変数
BRIGHTDATA_API_KEYに Bright Data の API キーが設定されていること
export BRIGHTDATA_API_KEY=your_api_key_here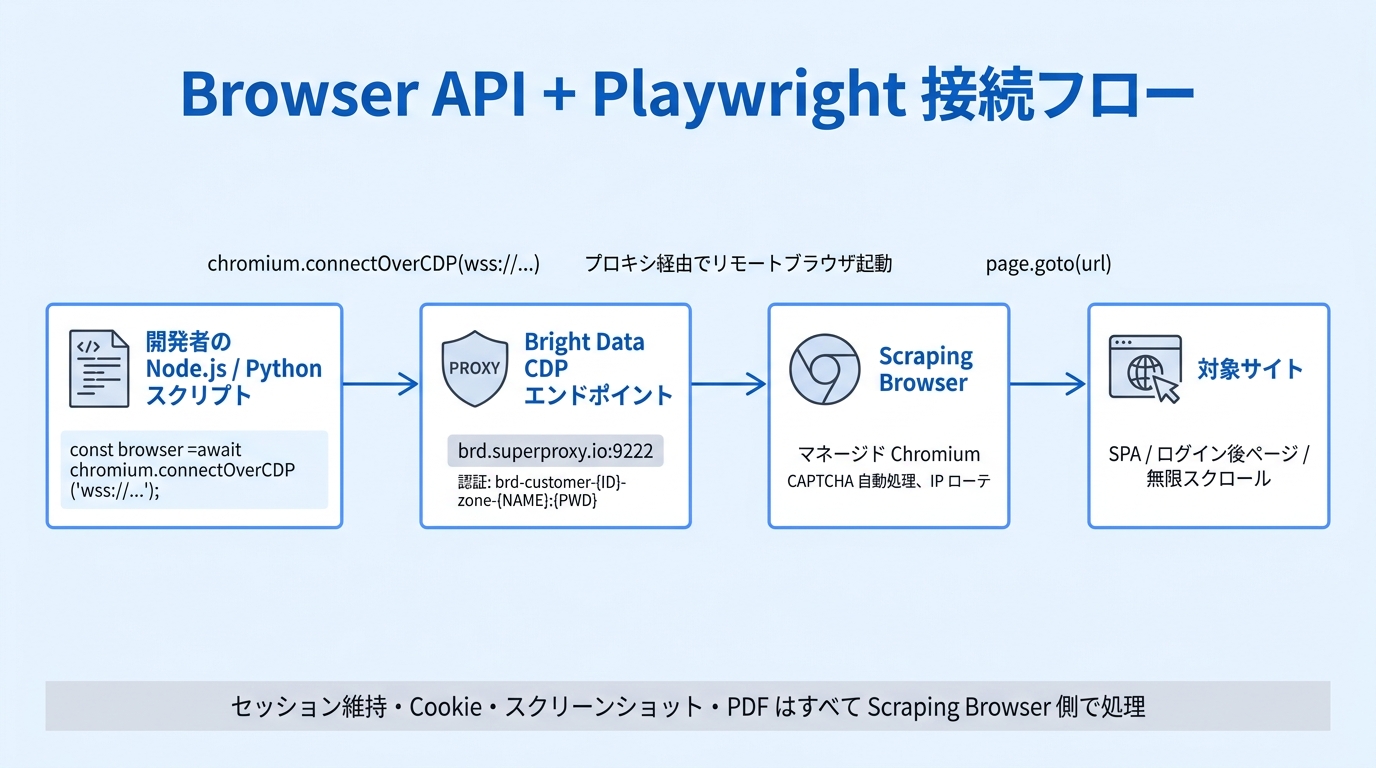
手順 1: CDP 接続文字列の組立
Scraping Browser の CDP エンドポイントは次の形式です。<CUSTOMER_ID>、<ZONE_NAME>、<PASSWORD> は Bright Data コンソールで確認してください。
wss://brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD>@brd.superproxy.io:9222
例として、環境変数から組み立てるシェルスクリプトを示します。
#!/usr/bin/env bash
CUSTOMER_ID=${BRIGHTDATA_CUSTOMER_ID:-12345}
ZONE_NAME=${BRIGHTDATA_ZONE_NAME:-myzone}
PASSWORD=${BRIGHTDATA_ZONE_PASSWORD:-pwd123}
CDP_URL="wss://brd-customer-${CUSTOMER_ID}-zone-${ZONE_NAME}:${PASSWORD}@brd.superproxy.io:9222"
export BRIGHTDATA_CDP_URL="${CDP_URL}"
echo "CDP URL: $BRIGHTDATA_CDP_URL"注意:CDP は WebSocket(
wss://)プロトコルなのでcurlで直接叩いて挙動を確認することはできません。実際に接続できるかは Playwright のconnectOverCDPで試すのが確実です(後述)。curl -I https://brd.superproxy.io/で TLS の到達性だけは確認できます。
手順 2: Node.js + Playwright で接続し 1 ページ取得
- 必要パッケージをインストールします。
npm init -y
npm i playwright- 接続スクリプト
node_playwright_cdp.jsを作成します。
// node_playwright_cdp.js
const { chromium } = require('playwright');
(async () => {
const cdpUrl = process.env.BRIGHTDATA_CDP_URL;
if (!cdpUrl) {
console.error('BRIGHTDATA_CDP_URL が設定されていません。');
process.exit(1);
}
// CDP エンドポイントに接続
const browser = await chromium.connectOverCDP(cdpUrl);
const context = await browser.newContext();
const page = await context.newPage();
// 任意の URL を取得
await page.goto('https://example.com', { waitUntil: 'networkidle' });
console.log('ページタイトル:', await page.title());
// 後片付け
await context.close();
await browser.close();
})();- 実行します。
BRIGHTDATA_CDP_URL=$BRIGHTDATA_CDP_URL node node_playwright_cdp.js手順 3: Python + Playwright で同じ接続
- パッケージをインストールします。
pip install playwright
python -m playwright install- スクリプト
python_playwright_cdp.pyを作成します。
# python_playwright_cdp.py
import os
import asyncio
from playwright.async_api import async_playwright
async def main():
cdp_url = os.getenv("BRIGHTDATA_CDP_URL")
if not cdp_url:
raise RuntimeError("BRIGHTDATA_CDP_URL が設定されていません。")
async with async_playwright() as p:
browser = await p.chromium.connect_over_cdp(cdp_url)
context = await browser.new_context()
page = await context.new_page()
await page.goto("https://example.com", wait_until="networkidle")
title = await page.title()
print(f"ページタイトル: {title}")
await context.close()
await browser.close()
asyncio.run(main())- 実行します。
BRIGHTDATA_CDP_URL=$BRIGHTDATA_CDP_URL python python_playwright_cdp.py手順 4: ログインフロー(フォーム入力 → クッキー保存)
以下は例として、GitHub のログインページに対してフォーム入力し、クッキーをローカルに保存する手順です。実際のサイトに合わせてセレクタを変更してください。
Node.js
// login_and_save_cookies.js
const { chromium } = require('playwright');
const fs = require('fs');
(async () => {
const cdpUrl = process.env.BRIGHTDATA_CDP_URL;
const browser = await chromium.connectOverCDP(cdpUrl);
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://github.com/login', { waitUntil: 'networkidle' });
await page.fill('input[name="login"]', process.env.GITHUB_USERNAME);
await page.fill('input[name="password"]', process.env.GITHUB_PASSWORD);
await page.click('input[name="commit"]');
await page.waitForNavigation({ waitUntil: 'networkidle' });
// クッキー取得・保存
const cookies = await context.cookies();
fs.writeFileSync('github_cookies.json', JSON.stringify(cookies, null, 2));
console.log('クッキーを github_cookies.json に保存しました');
await context.close();
await browser.close();
})();Python
# login_and_save_cookies.py
import os
import json
import asyncio
from playwright.async_api import async_playwright
async def main():
cdp_url = os.getenv("BRIGHTDATA_CDP_URL")
async with async_playwright() as p:
browser = await p.chromium.connect_over_cdp(cdp_url)
context = await browser.new_context()
page = await context.new_page()
await page.goto("https://github.com/login", wait_until="networkidle")
await page.fill('input[name="login"]', os.getenv("GITHUB_USERNAME"))
await page.fill('input[name="password"]', os.getenv("GITHUB_PASSWORD"))
await page.click('input[name="commit"]')
await page.wait_for_navigation(wait_until="networkidle")
cookies = await context.cookies()
with open("github_cookies.json", "w", encoding="utf-8") as f:
json.dump(cookies, f, indent=2, ensure_ascii=False)
print("クッキーを github_cookies.json に保存しました")
await context.close()
await browser.close()
asyncio.run(main())ポイント:取得したクッキーは後続のリクエストで
context.add_cookies(cookies)とすればセッションを再利用できます。
手順 5: 無限スクロール・遅延読み込みの待機パターン
無限スクロールはページの下部までスクロールし、追加コンテンツがロードされるのを待つループで実装します。
Node.js
// infinite_scroll.js
const { chromium } = require('playwright');
(async () => {
const cdpUrl = process.env.BRIGHTDATA_CDP_URL;
const browser = await chromium.connectOverCDP(cdpUrl);
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://example-infinite-scroll.com', { waitUntil: 'networkidle' });
// 10 回スクロールしてみる
for (let i = 0; i < 10; i++) {
await page.evaluate(() => {
window.scrollTo(0, document.body.scrollHeight);
});
// 新しいコンテンツがロードされるまで 2 秒待機
await page.waitForTimeout(2000);
}
// 取得した HTML を保存
const html = await page.content();
const fs = require('fs');
fs.writeFileSync('infinite_scroll.html', html);
console.log('ページ内容を infinite_scroll.html に保存しました');
await context.close();
await browser.close();
})();Python
# infinite_scroll.py
import os
import asyncio
from playwright.async_api import async_playwright
async def main():
cdp_url = os.getenv("BRIGHTDATA_CDP_URL")
async with async_playwright() as p:
browser = await p.chromium.connect_over_cdp(cdp_url)
context = await browser.new_context()
page = await context.new_page()
await page.goto("https://example-infinite-scroll.com", wait_until="networkidle")
for _ in range(10):
await page.evaluate("window.scrollTo(0, document.body.scrollHeight);")
await page.wait_for_timeout(2000) # 2 秒待機
html = await page.content()
with open("infinite_scroll.html", "w", encoding="utf-8") as f:
f.write(html)
print("ページ内容を infinite_scroll.html に保存しました")
await context.close()
await browser.close()
asyncio.run(main())手順 6: スクリーンショット / PDF 出力
取得したページをそのままスクリーンショットや PDF に保存できます。
Node.js
// screenshot_and_pdf.js
const { chromium } = require('playwright');
const fs = require('fs');
(async () => {
const cdpUrl = process.env.BRIGHTDATA_CDP_URL;
const browser = await chromium.connectOverCDP(cdpUrl);
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://example.com', { waitUntil: 'networkidle' });
// スクリーンショット
await page.screenshot({ path: 'example.png', fullPage: true });
console.log('スクリーンショットを example.png に保存');
// PDF(Chromium のみ対応)
await page.pdf({ path: 'example.pdf', format: 'A4' });
console.log('PDF を example.pdf に保存');
await context.close();
await browser.close();
})();Python
# screenshot_and_pdf.py
import os
import asyncio
from playwright.async_api import async_playwright
async def main():
cdp_url = os.getenv("BRIGHTDATA_CDP_URL")
async with async_playwright() as p:
browser = await p.chromium.connect_over_cdp(cdp_url)
context = await browser.new_context()
page = await context.new_page()
await page.goto("https://example.com", wait_until="networkidle")
await page.screenshot(path="example.png", full_page=True)
print("スクリーンショットを example.png に保存")
await page.pdf(path="example.pdf", format="A4")
print("PDF を example.pdf に保存")
await context.close()
await browser.close()
asyncio.run(main())ローカル Chrome との違い
| 項目 | ローカル Chrome | Bright Data Scraping Browser |
|---|---|---|
| 接続方式 | chrome://inspect(ローカルデバッガ) | CDP エンドポイント(wss://…) |
| 帯域 | 自己ネットワーク | Bright Data のプロキシ帯域(自動圧縮・最適化) |
| タイムアウト | ローカル環境依存 | デフォルト 30 s(必要に応じて timeout オプションで変更) |
| セッション保持 | ブラウザプロファイルで管理 | クッキー・ローカルストレージは context に保存し、再利用可能 |
| CAPTCHA 回避 | 手動 or サードパーティー | Bright Data の自動 CAPTCHA 解決オプション(captcha_solver パラメータ)を併用可能 |
検証
- ページタイトルが取得できているか(例:
Example Domain) - クッキーが
github_cookies.jsonに保存され、次回リクエストでcontext.add_cookies()が成功するか - 無限スクロール後の HTML に期待した要素(例: 商品リスト)が含まれているか
- スクリーンショット / PDF が正しく出力され、内容が閲覧できるか
上記がすべてクリアできれば、Step 5 は完了です。
次に読む
- /usecases/UC-WEB-002 – 大規模 JavaScript 描画サイトの高速抽出
- /usecases/UC-DEV-009 – CAPTCHAs と対話的ログインのベストプラクティス
- /hands-on/step-6-mcp-agent – MCP エージェントでのマルチプロキシ制御
以上で「Step 5 Browser API + Playwright」の解説は終了です。お疲れさまでした。