Bright Data を日本語で学べる、非公式ポータル
Bright Dataを日本語で
プロキシ・スクレイピング API・既製データセットを束ねたWeb データ取得プラットフォームの使い方を、初心者から実務運用まで段階的に学べます。
入門(Lv1)→ 実装(Lv2)→ 応用(Lv3)→ AI 実践(Lv4)→ 運用(Lv5)の5 段階レベル設計で、迷わず次の一歩が決まる。
- 40
- ユースケース
- 6
- ハンズオン
- 15
- 図解
- Lv1→Lv5
- 学習レベル
6 カテゴリ
curl/Py/Node
全ページ網羅
入門→運用
このサイトで学べる全体像
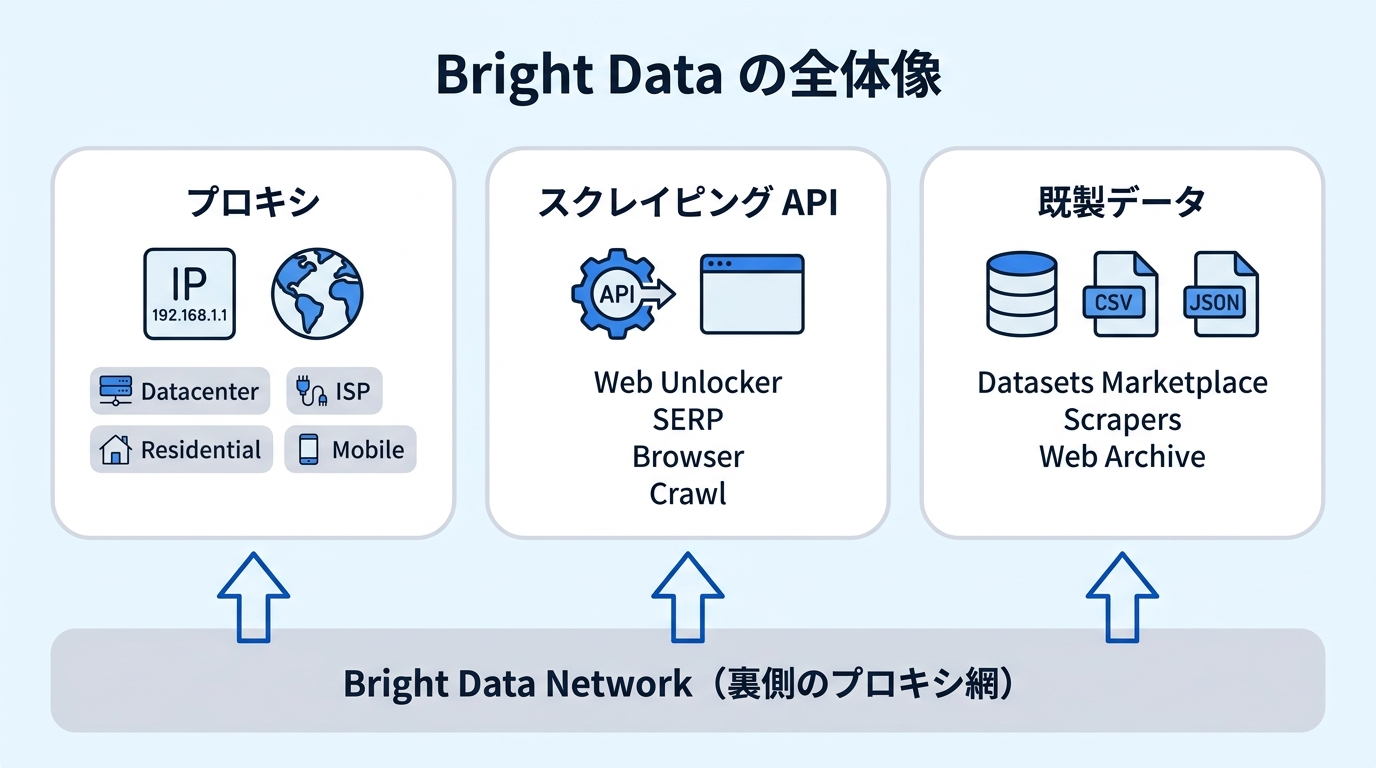
3 つの軸で構成
Lv1–Lv5 プレビュー
すべて見る →Lv1
Lv1 入門
認証、最初の API コール、レスポンス形式を理解する。
目安 2–4 時間
Lv2
Lv2 実装
SERP API / Web Unlocker / Browser API など単機能 API を使ってミニ機能を作る。
目安 4–8 時間
Lv3
Lv3 応用
Scraper API・Data Feeds・非同期ジョブ・Webhook を取り入れる。
目安 8–16 時間
Lv4
Lv4 AI 実践
MCP や LangChain などを使い、検索・抽出・要約のエージェントを構築する。
目安 12–24 時間
Lv5
Lv5 運用
権限分離、監視、コスト管理、品質評価(Grounding)まで実装する。
目安 継続運用
注目ユースケース
40 件すべて →- UC-WEB-001Web AccessLv2
保護サイトの安定収集基盤
ブロック/レート制限/CAPTCHA を吸収し、アプリ連携に耐えるデータ取得基盤を作る。
- UC-SERP-001SERPLv2
Organic Keyword Tracking(順位監視)
キーワード順位の定点観測を自動化し、変動を検知する。
- UC-CRAWL-001CrawlLv3
AI / LLM 学習データ収集
ドメイン横断クロールで Markdown / JSON 化し、RAG・学習データの前処理に投入する。
- UC-AI-001AILv4
Agent Web Access(検索+抽出+ブラウザ自動化)
AI エージェントに Web 検索・抽出・ブラウザ操作を持たせ、業務タスクを自律化する。
- UC-AI-004AILv4
Answer Engine(根拠付きリアルタイム回答)
高並列な回答生成基盤に引用と鮮度保証を与え、プロダクション品質の回答を返す。
- UC-DEV-003DeveloperLv4
MCP Server で AI クライアント接続
Claude/Cursor 等の AI クライアントから MCP 経由で Bright Data に接続する。
6 本のハンズオン
Lv1 ・ 目安 45 分
Step 1 認証完全ガイド
API Access / Native Access の両方で「最初の 1 回」を curl / Python / Node で通し、権限モデルとキー運用の型を身につける。
Lv2 ・ 目安 90 分
Step 2 SERP 順位監視パイプライン
SERP API で日次クエリ → CSV / SQLite に保存 → 変動検知アラートまでの最小パイプラインを作る。
Lv3 ・ 目安 120 分
Step 3 Crawl API で RAG 前処理
複数 URL を Crawl API で取得し、Markdown に整形、最小 RAG の入力として取り込む。
Lv3 ・ 目安 90 分
Step 4 Amazon / YouTube 分析
Scraper API で EC/動画領域の構造化データを取得し、最小限の分析ノートブックを回す。
Lv3 ・ 目安 120 分
Step 5 Browser API + Playwright
Browser API と Playwright を接続し、JS 描画サイトから必要データを抽出する。
Lv4 ・ 目安 90 分
Step 6 MCP + AI エージェント連携
MCP Server を Claude / Cursor に接続し、Bright Data を使った引用付き回答を生成する。
最短の次の 1 歩
迷ったら Step 1「認証完全ガイド」から。curl で最初の 1 コールを通すところまで案内します。
Step 1 を始める →