UC-AI-004AILv4Lv5
Answer Engine(根拠付きリアルタイム回答)
高並列な回答生成基盤に引用と鮮度保証を与え、プロダクション品質の回答を返す。
Answer EngineSERP APIWeb UnlockerMCPData Feeds
KPI 例
- 回答遅延
- 引用率
- 検証通過率
Answer Engine の要点は、LLM に答えさせること自体ではなく、どのソースを見て答えたかを返せる状態にする ことです。Bright Data の AI ユースケースでは、検索、取得、引用付き回答を一連で扱う構成が案内されており、実装では SERP API、必要に応じて Web Unlocker、継続的な入力源として Data Feeds を組み合わせる整理がわかりやすいです。
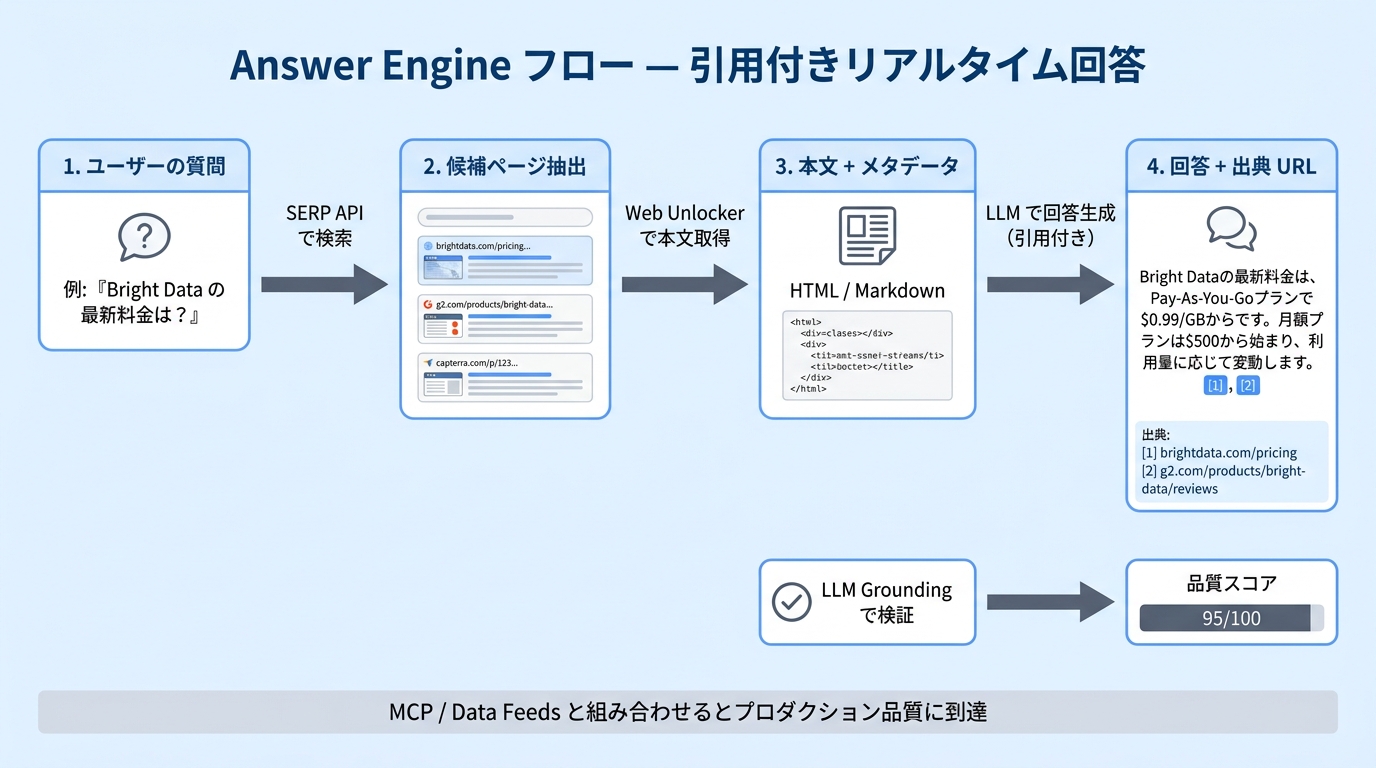
誰の課題か
- 自社チャットボットに最新の外部情報を参照させたいプロダクト開発者
- サポート回答に根拠 URL を必ず添えたい運用チーム
- 社内ナレッジだけでは足りず、公開 Web も参照したい AI アプリ担当
ここで重視すべきなのは回答品質より先に、引用の一貫性です。回答が長いか短いかより、出典 URL を安定して返せるかどうかを先に固めます。
推奨製品セット
| 製品 | 役割 | 使いどころ |
|---|---|---|
| Answer Engine | ユースケース全体の設計単位 | 回答生成と引用付与の流れを定義する |
| SERP API | 最新情報の入口 | 質問に応じた検索結果を取る |
| Web Unlocker | 検索後の単発取得 | SERP 以外の本文取得が必要なときに使う |
| Data Feeds | 継続的な構造化データ供給 | 定期更新データを回答に混ぜる |
| MCP | AI クライアント連携 | エージェントから検索ツールを呼ぶ |
- 検索結果だけで回答可能な質問と、本文取得が必要な質問を分けて扱います。
- 反復質問が多い領域では、毎回検索するより Data Feeds や既存ストアを優先したほうが安定します。
最小実装イメージ
このページでは、Step 6 に合わせて MCP の検索結果から「回答 + 引用」を組み立てる最小例を示します。
import os
import requests
API_KEY = os.getenv("BRIGHTDATA_API_KEY")
def search_with_mcp(query: str) -> list[dict]:
response = requests.post(
"http://localhost:8080/v1/search",
headers={
"Content-Type": "application/json",
"X-API-KEY": API_KEY,
},
json={
"query": query,
"engine": "google",
"num_results": 3,
},
timeout=30,
)
response.raise_for_status()
return response.json().get("results", [])
def format_answer(question: str) -> str:
results = search_with_mcp(question)
evidence = []
citations = []
for index, item in enumerate(results, start=1):
evidence.append(item.get("snippet", ""))
citations.append(f"[{index}] {item.get('url')}")
answer = "\n".join(evidence[:2]).strip()
return f"{answer}\n\n引用:\n" + "\n".join(citations)
if __name__ == "__main__":
print(format_answer("Bright Data answer engine overview"))これは最小構成なので、本文取得や要約モデルは外部に切り出していません。実運用では「検索結果のスニペットだけで答える」「Unlocker で本文を追加取得する」「定期データは Data Feeds を見る」の 3 分岐を持たせると回答品質が安定します。
運用ポイント
- 引用 URL は回答本文と別フィールドで保持します。表示用の整形で失われると監査しづらくなるためです。
- 検索結果のスニペットだけで十分な質問と、本文確認が必要な質問を分けます。すべてに本文取得を入れると遅く、コストも上がります。
- Data Feeds や社内ナレッジのような安定ソースがある領域では、それを第一候補にし、Web 検索は補助に回します。
- 回答の正しさを測る前に、引用率、引用切れ率、取得日時の欠落率を監視します。
- 質問カテゴリごとに利用プロダクトを切り替えられるようにし、同じパイプラインで何でも処理しないことが重要です。