Lv4 ・ 90 分
Step 6 AI エージェント連携(ビジネス向け)
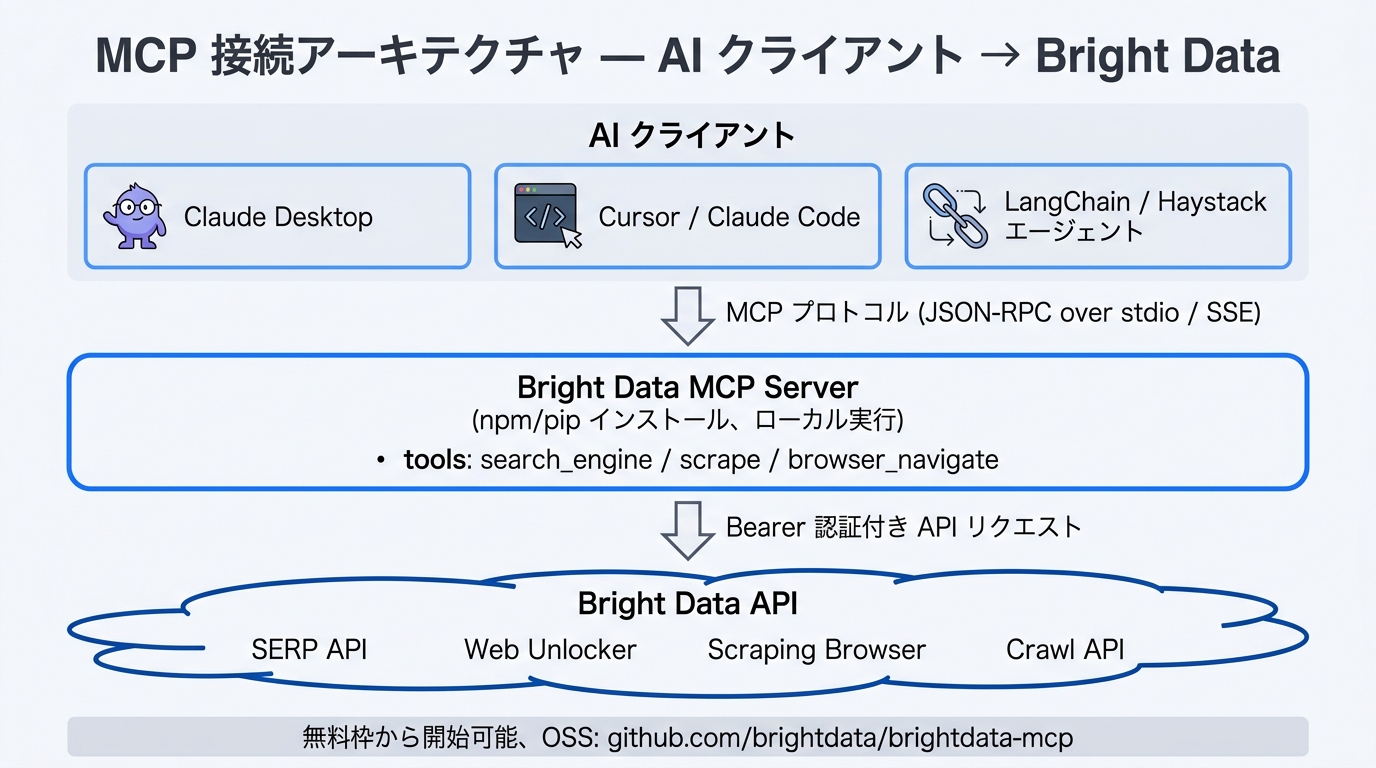
コードを書かずに、Claude Desktop や Dify の AI エージェントから Bright Data を使えるようにする。
このハンズオンでは、Bright Data を AI エージェントの調査ツールとして使える状態にします。ポイントは、コードを書くことではなく、AI が必要に応じて検索、ページ取得、ナレッジ参照を使い分けられるようにすることです。
個人なら Claude Desktop、チーム共有なら Dify が向いています。
ゴールと所要時間
- ゴール: AI エージェントが Bright Data を使って調査し、引用つきで回答できる状態にする
- 所要時間: 約 90 分
- 難易度: Lv4
前提
- Step 1 認証(ビジネス向け) が完了している
- Claude Desktop または Dify を使える
- 調査テーマが 1 つ決まっている
まず決めること
| 利用形態 | 向いているツール |
|---|---|
| 個人で調査を速くしたい | Claude Desktop |
| チームで共有 AI を作りたい | Dify |
| 定期実行まで含めたい | Dify + n8n |
手順 1: AI に持たせる役割を決める
最初のエージェントは、役割を絞ったほうがうまくいきます。例:
- 競合ニュース調査エージェント
- 商談前の企業調査エージェント
- SEO 変動の要点整理エージェント
- EC 商品比較エージェント
手順 2A: Claude Desktop で使う
Claude Desktop では、接続設定後にプロンプト設計を整えるだけでかなり実用になります。最初の指示文例:
あなたは市場調査アシスタントです。
Bright Data を使って最新の公開情報を取得してください。
回答には必ず出典 URL を付け、推測で埋めないでください。質問例:
競合 3 社の直近 7 日のニュースを調べ、
会社名、ニュース要点、事業インパクト、出典 URL を表にしてください。手順 2B: Dify で使う
Dify では、エージェント的な振る舞いをワークフローとして固定できます。最小構成は次のとおりです。
- 入力ノード
- Bright Data を呼ぶ HTTP Request ノード
- 必要ならナレッジ検索ノード
- LLM ノード
- 出力ノード
LLM ノードの指示文例:
取得した公開情報だけを根拠に回答してください。
回答には必ず出典 URL を含めてください。
事実と解釈を分けてください。手順 3: 出力形式を固定する
AI エージェントは、形式を決めるだけでかなり使いやすくなります。おすすめは次の 4 列です。
- 事実
- 要点
- 次のアクション
- 出典 URL
この形なら、役員報告、営業準備、広報共有のどれにも流しやすくなります。
手順 4: 質問の粒度を整える
よくない例:
競合を調べてよい例:
競合 3 社の日本市場向けニュースを、過去 7 日に絞って調べてください。
資金調達、人事、大型提携、新サービス開始に絞り、
表形式で出典 URL つきで返してください。手順 5: 品質確認のルールを置く
最初のうちは、毎回この 3 点を見ます。
- 出典 URL があるか
- URL を開くと本当にその内容か
- 古い情報や推測が混ざっていないか
手順 6: よく使う調査をテンプレート化する
一度うまくいった指示文は、毎回打ち直さずに残します。たとえば:
- 週次競合ニュース
- 商談前ブリーフィング
- 市場比較表
- 商品レビュー要約
Claude ならプロジェクト化、Dify ならアプリとして公開すると運用しやすいです。
実務でのコツ
出典を必須にする
使われる AI になるかどうかは、ここで決まります。
取得件数を絞る
最初は 5 件から 10 件の上位情報で十分です。必要以上に広げると、コストも解釈負荷も上がります。
ナレッジと最新検索を分ける
固定情報はナレッジ、最新動向は Web 取得、と分けると安定します。
完了の目安
- 1 つの調査テーマで、AI が安定して答えられる
- 出典 URL が毎回付く
- チーム内の誰かが同じ質問を再利用できる